인공지능 기술의 발전 속도가 날이 갈수록 빨라지고 있습니다. 특히 대규모 언어 모델(Large Language Model, LLM) 분야에서는 매달 새로운 모델이 등장하며 우리를 놀라게 하고 있죠. 그 중에서도 오늘 소개할 Llama 3.1은 오픈 소스 AI의 판도를 완전히 바꿀 수 있는 혁신적인 모델입니다. 405B(4050억)개의 파라미터를 가진 이 거대한 모델은 어떤 특징을 가지고 있을까요? 지금부터 자세히 알아보겠습니다.
라마 3.1 (Llama 3.1) 이란?
Llama 3.1은 Meta(구 Facebook)에서 2024년 7월 23일에 공개한 최신 대규모 언어 모델입니다. 이전 버전인 Llama 2에 비해 크게 향상된 성능을 자랑하며, 다양한 자연어 처리 작업에서 우수한 결과를 보여줍니다.

Llama 3.1의 주요 특징은 다음과 같습니다:
- 8B, 70B, 405B 등 다양한 모델 크기 제공
- 기존 모델 대비 성능 대폭 향상
- 오픈소스로 공개��되어 누구나 사용 가능
- 로컬 PC에서도 실행 가능 (소형 모델의 경우)
Llama 3.1의 주요 특징
1. 오픈 소스의 강점
Llama 3.1의 가장 큰 특징은 바로 '오픈 소스'라는 점입니다. Meta가 개발한 이 모델은 기존의 폐쇄적인 AI 모델들과는 달리, 누구나 활용하고 개선할 수 있는 개방형 모델입니다. 이는 AI 기술의 민주화와 혁신 가속화에 큰 기여를 할 것으로 기대됩니다.
2. 405B 파라미터의 거대한 규모
Llama 3.1의 405B 파라미터 모델은 현재까지 공개된 오픈 소스 모델 중 가장 큰 규모를 자랑합니다. 이는 GPT-4와 같은 최첨단 폐쇄형 모델들과 견줄 만한 성능을 보여줄 수 있음을 의미합니다.
3. 다국어 지원
Llama 3.1은 8개 언어를 지원하는 다국어 모델입니다. 이는 글로벌 사용자들에게 더 나은 서비스를 제공할 수 있게 해줍니다.
4. 확장된 컨텍스트 길이
이전 버전에 비해 크게 늘어난 128K 토큰의 컨텍스트 길이를 지원합니다. 이를 통해 더 긴 문서나 대화를 한 번에 처리할 수 있게 되었습니다.
Llama 3.1의 기술적 혁신
Llama 3.1은 단순히 크기만 큰 모델이 아닙니다. 여러 가지 기술적 혁신을 통해 성능과 효율성을 높였습니다.
모델 아키텍처 최적화
Llama 3.1은 표준 디코더 전용 트랜스포머 모델을 기반으로 하되, 학습 안정성을 극대화하기 위해 일부 수정을 가했습니다. 특히 전문가 혼합(Mixture of Experts) 모델 대신 단일 모델 구조를 채택하여 학습의 안정성을 높였습니다.
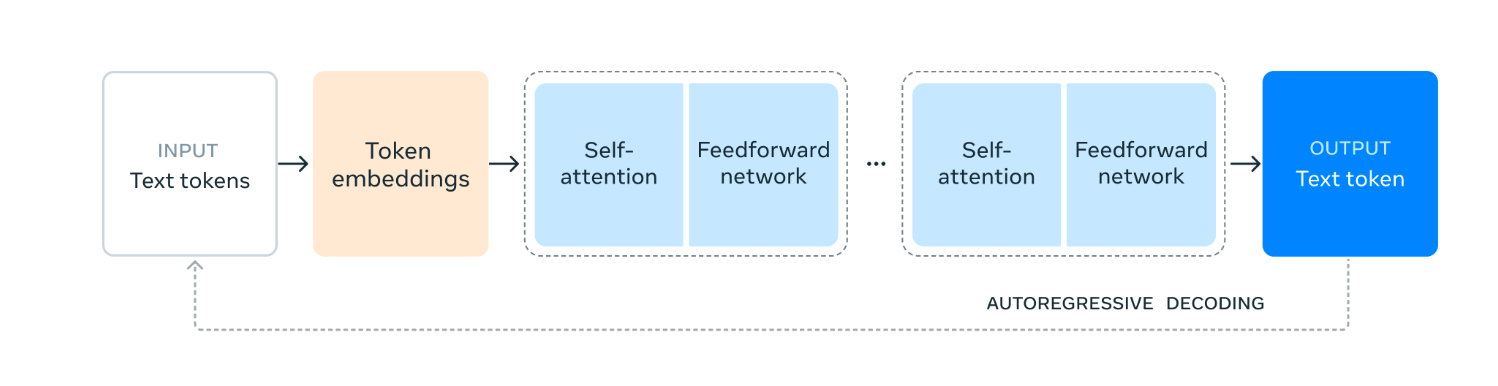
데이터 품질 개선
사전 학습 및 후처리 과정에서 데이터의 양과 질을 모두 개선했습니다. 더 신중한 전처리 파이프라인과 엄격한 품질 보증 과정을 거쳐 고품질의 데이터만을 사용했습니다.
반복적 후처리 기법
지도 학습 미세 조정(Supervised Fine-Tuning)과 직접 선호도 최적화(Direct Preference Optimization)를 반복적으로 적용하는 후처리 기법을 도입했습니다. 이를 통해 각 능력의 성능을 점진적으로 향상시켰습니다.
Llama 3.1의 성능 평가
Llama 3.1의 성능은 어떨까요? Meta에서 발표한 벤치마크 결과를 살펴보겠습니다.
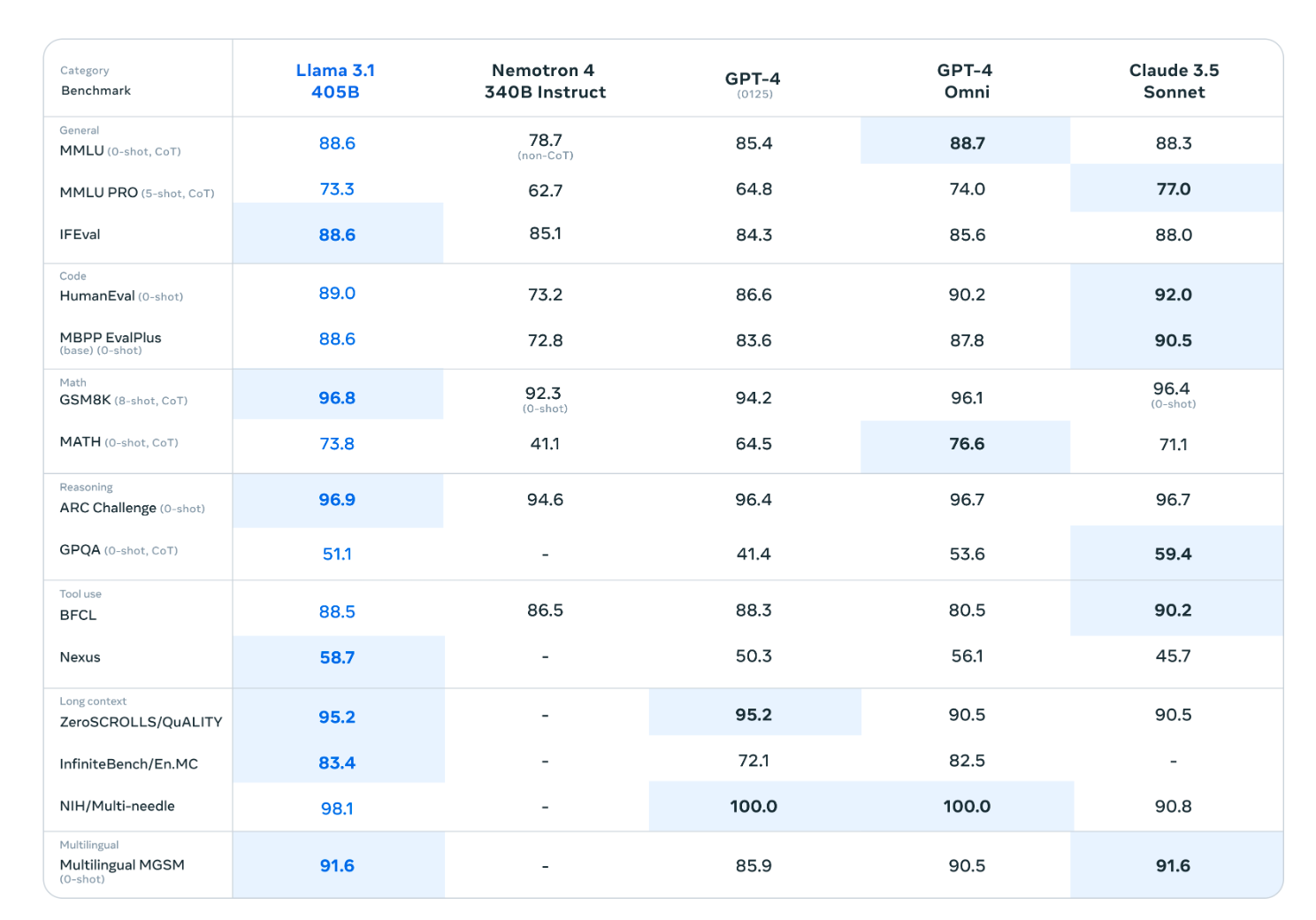
위 벤치마크 결과에서 볼 수 있듯이, Llama 3.1 405B 모델은 최신 폐쇄형 모델들과 견줄 만한 성능을 보여주고 있습니다. 특히 오픈 소스 모델임에도 불구하고 이러한 성능을 달성했다는 점이 주목할 만합니다.
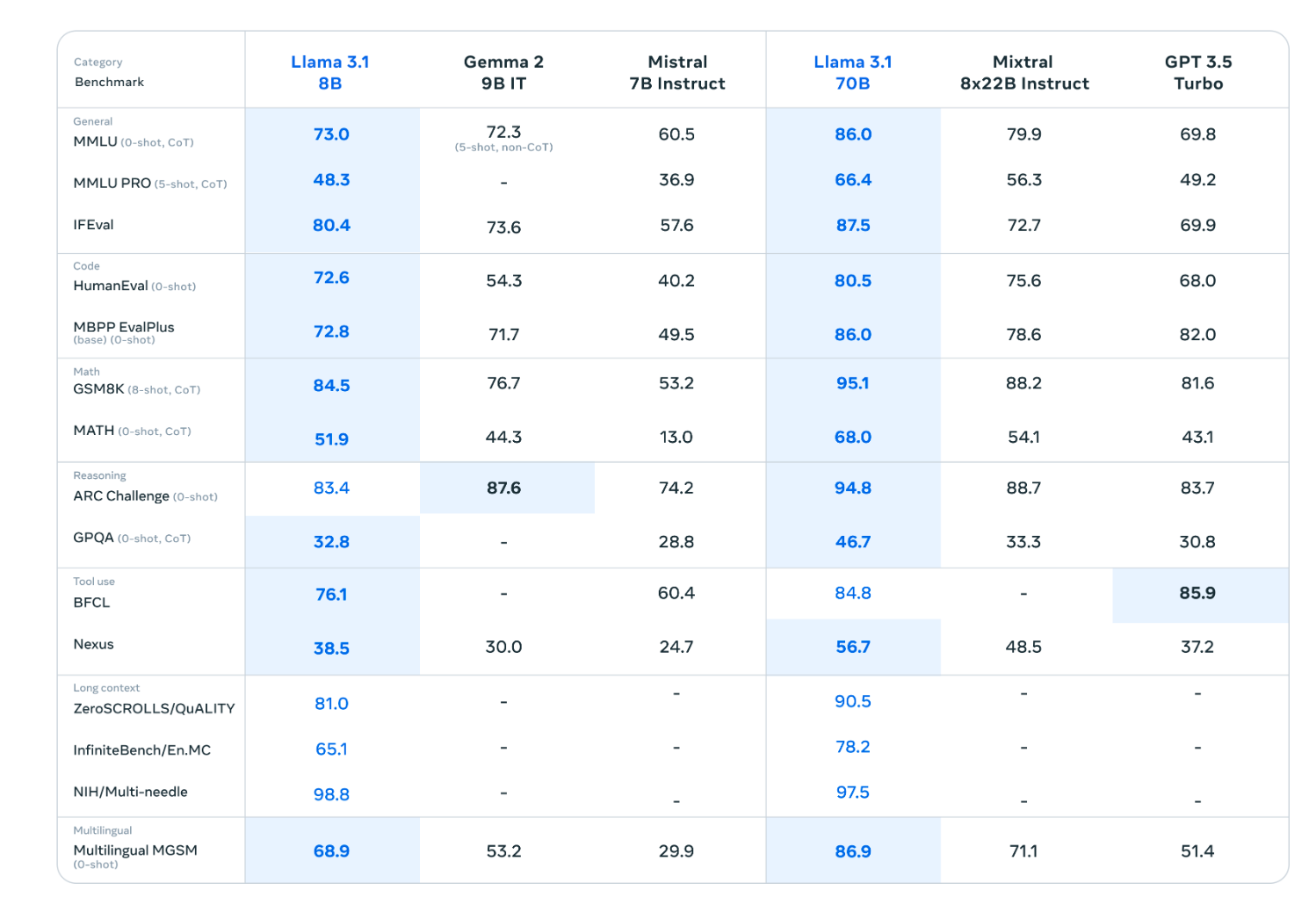
또한 Llama 3.1 8B와 같은 작은 규모의 모델도 높은 성능을 보여주고 있습니다. 이는 소규모 기업이나 개인 사용자들에게도 접근성을 제공한다는 점에서 의미가 있습니다.
�아래는 Llama 3.1 405B의 Human 평가 결과입니다.
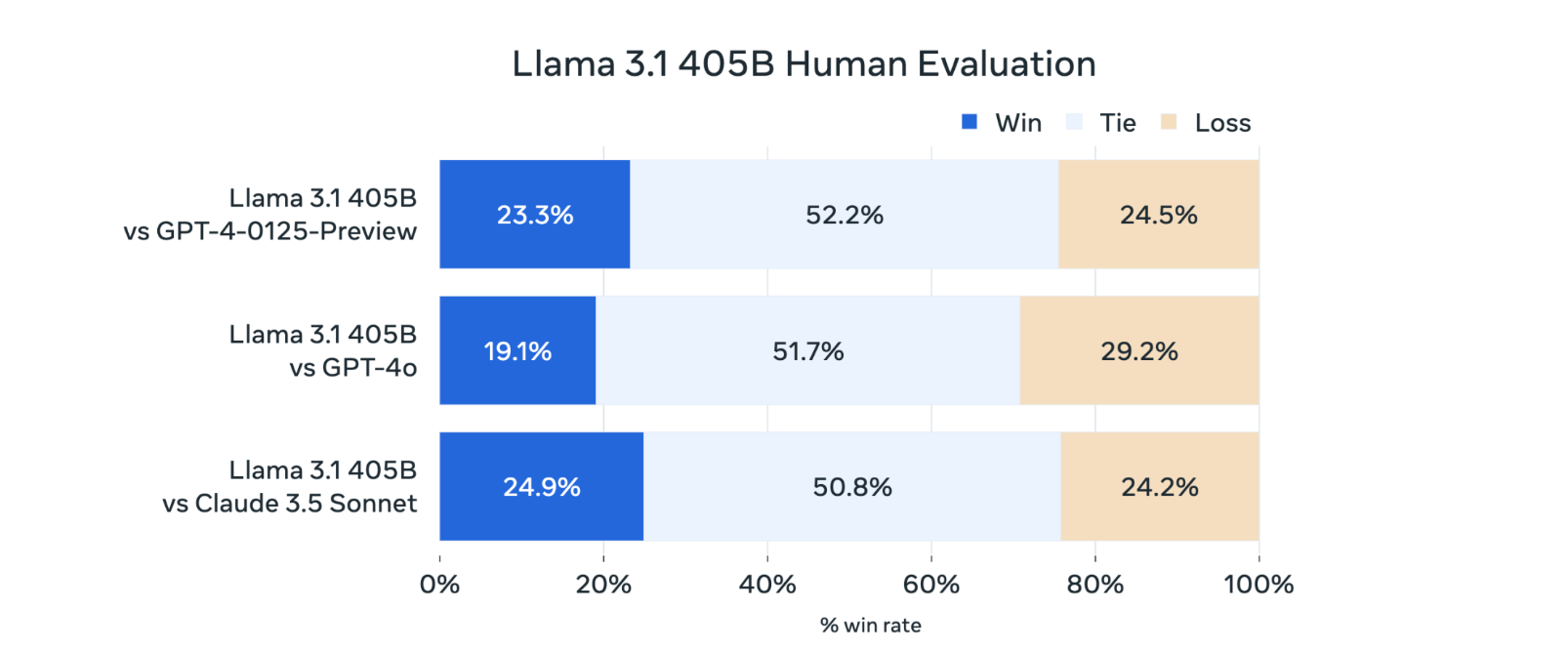
Llama 3.1의 활용 방안
Llama 3.1은 다양한 분야에서 활용될 수 있습니다. 몇 가지 예시를 살펴보겠습니다:
- 자연어 처리 (NLP) 애플리케이션: 챗봇, 문서 요약, 감성 분석 등
- 코드 생성 및 디버깅: 프로그래밍 보조 도구로 활용
- 다국어 번역 서비스: 8개 언어 지원을 활용한 번역 시스템
- 교육 보조 도구: 학습 자료 생성, 질문 답변 등
- 연구 및 개발: 새로운 AI 모델 개발을 위한 기반 모델로 활용
Llama 3.1의 미래와 과제
Llama 3.1은 오픈 소스 AI의 새로운 지평을 열었지만, 동시에 몇 가지 과제도 안고 있습니다.
1. 윤리적 사용 보장
강력한 AI 모델의 오픈 소스화는 악용 가능성에 대한 우려를 낳습니다. Meta는 이를 위해 Llama Guard 3와 Prompt Guard 등의 안전 도구를 함께 공개했지만, 커뮤니티의 책임 있는 사용이 중요합니다.
2. 계산 자원의 문제
405B 파라미터의 거대 모델을 운용하기 위해서는 엄청난 컴퓨팅 파워가 필요합니다. 이는 개인이나 소규모 기업의 접근성을 제한할 수 있는 요소입니다.
3. 지속적인 개선 필요성
AI 기술의 빠른 발전 속도를 고려할 때, Llama 3.1도 지속적인 업데이트와 개선이 필요할 것입니다. 오픈 소스 커뮤니티의 적극적인 참여가 모델의 미래를 좌우할 것입니다.
Llama 3.1 사용하기
Llama 3.1을 사용해보고 싶다면 다음과 같은 방법들이 있습니다:
-
허깅페이스(Hugging Face)에서 사용하기
- 허깅페이스 Llama 3.1 페이지에서 모델을 직접 시험해볼 수 있습니다.
-
Meta AI 서비스 이용하기
- Meta AI 웹사이트에서 Llama 3.1을 기반으로 한 AI 서비스를 체험할 수 있습니다.
-
로컬 PC에서 실행하�기
- 소형 모델(예: 8B)의 경우, 로컬 PC에서도 실행이 가능합니다. Llama GitHub 저장소에서 관련 코드와 지침을 확인할 수 있습니다.
-
클라우드 서비스 활용하기
- AWS, Google Cloud, Azure 등 주요 클라우드 제공업체들이 Llama 3.1을 지원합니다. 각 플랫폼의 AI 서비스를 통해 Llama 3.1을 사용해볼 수 있습니다.
결론
Llama 3.1은 오픈 소스 AI의 새로운 이정표를 세웠습니다. 405B 파라미터의 거대 모델을 공개함으로써, Meta는 AI 기술의 민주화와 혁신 가속화에 큰 기여를 했습니다. 앞으로 Llama 3.1이 AI 생태계에 어떤 변화를 가져올지, 그리고 이를 통해 어떤 혁신적인 애플리케이션들이 탄생할지 기대가 됩니다.
우리는 AI 기술의 발전이 가져올 혜택과 동시에 잠재적 위험에 대해서도 주의를 기울여야 합니다. Llama 3.1과 같은 강력한 도구를 책임감 있게 사용하고, 윤리적 가이드라인을 준수하는 것이 중요합니다. 이를 통해 우리는 AI 기술의 혜택을 최대화하면서도 부작용을 최소화할 수 있을 것입니다.
Llama 3.1은 단순한 AI 모델이 아닌, 새로운 가능성의 문을 여는 열쇠입니다. 이제 우리에게 남은 과제는 이 열쇠를 어떻게 사용할 것인가 하는 것입니다. AI의 미래는 우리의 손에 달려 있습니다.
보다 자세한 내용이 궁금하다면 Meta AI 공식 문서에서 Llama 3.1에 대한 자세한 정보를 확인해보세요.